- 1 Post
- 11 Comments



 6·15 days ago
6·15 days agoDunno about war, but the CENTCOM release is pretty clear-cut:
The blockade will be enforced impartially against vessels of all nations entering or departing Iranian ports and coastal areas
Many people seem to have this confused.
- The US blockade is on (as currently implemented) the Gulf of Oman, not the Strait of Hormuz.
- As far as I know, one tanker, Elpis, has transited the Strait, and then stopped – I have to assume was stopped, by somebody – a short way into the Gulf.
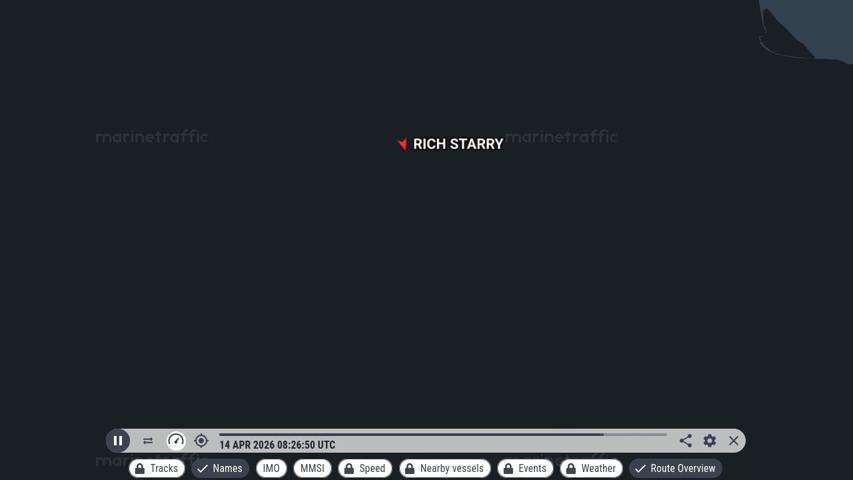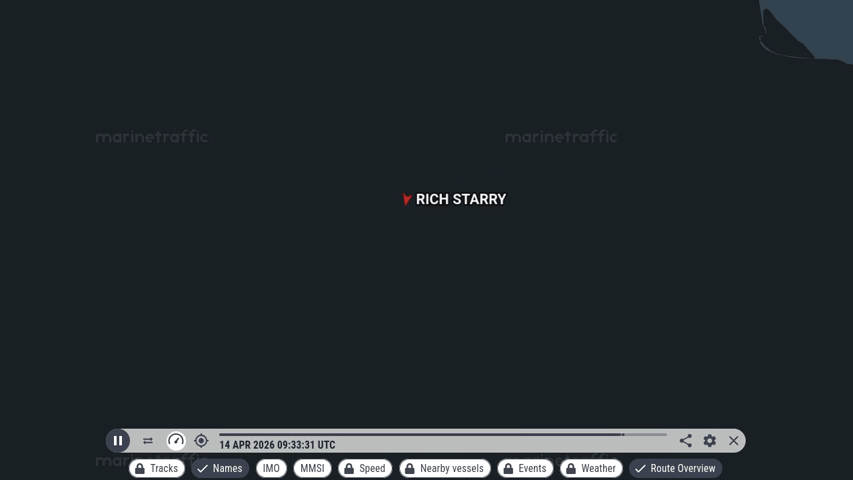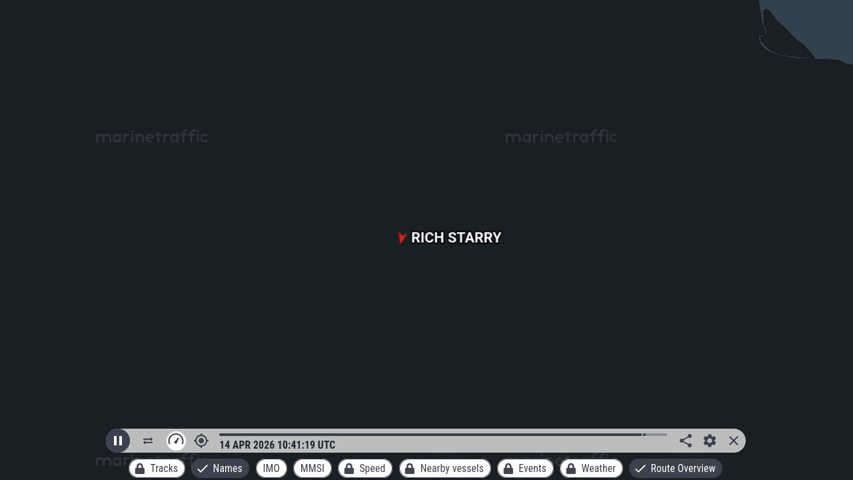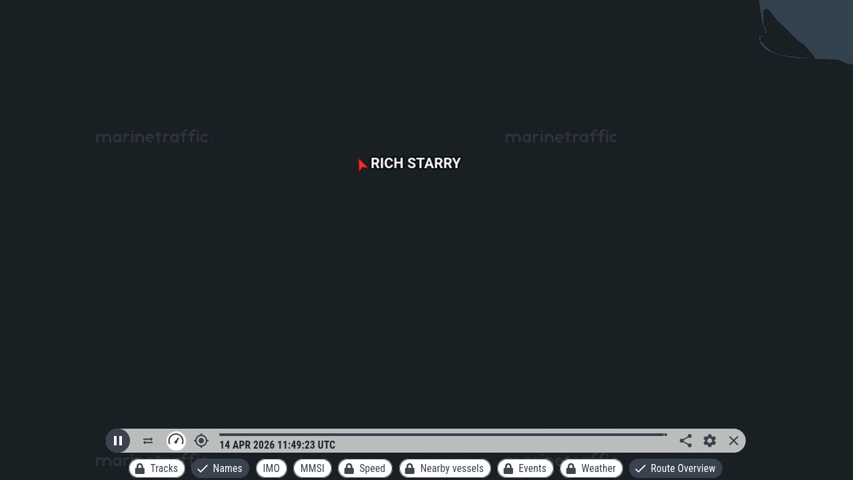
- Rich Starry has not yet passed the Gulf. It has not even reached the point where Elpis stopped, but it’s on track to do so pretty soon.
- Elpis departed an Iranian port. This directly defies the stated US blockade.
- Rich Starry departed the UAE, which does not actually violate the stated US blockade (which explicitly allows ships transiting “to and from non-Iranian ports”).
- Rich Starry is under US sanctions due to previously being determined as aiding Iran. It is also Chinese-owned. Unclear how these factors will play into things.
So in summary Rich Starry hasn’t passed the US blockade yet, and even if it does that says nothing about the effectiveness of the blockade, because by the blockade’s wording it should be allowed through anyway.
Source https://xcancel.com/DropSiteNews/status/2043921010311741860, CENTCOM, and AIS data.
Edit 10:30 UTC: https://www.marinetraffic.com/ shows no AIS updates from Starry in the last 2 hours, seems like it stopped sending data in a similar area to Elpis. AIS didn’t actually show the ship coming to a stop, just a lack of updates. The last update had it keeping course at a relatively fast 8.1 knots. I read that there may be GPS jamming and other stuff going on in the area, so not sure what this really means.
Edit 2 12:00 UTC: nope, they are outttta there. I’m guessing they’re not going to China today.
 39·2 months ago
39·2 months agoIs it really not as easy for them as saying “hey btw don’t use this distro if you’re in California” and fully expecting nobody to comply? I’m not sure if Ubuntu is based in Cali in which case I can see it being more difficult.
Also this “age bracket” thing seems to have an obvious flaw in that any application that’s running semi-regularly can just poll the API every day and find out the user’s DOB by checking when they roll into the next bracket. It’s actually leaking more data about children than about adults in that case. Brilliant.
My first answer is “WTF is RTK?”; my answer after consulting Wikipedia is “no, they’re separate things”.
RTK doesn’t sound like it broadcasts any data out but I barely understood what I just read. The Wikipedia coverage on this whole topic seems rather poor quality, I don’t think it’s just because I’m dumb.

It’s not as clear-cut as most people here are saying.
In short, GPS itself is just listening to satellites, and nothing is leaked that way, but most modern phones use “Assisted GPS” of some sort. The most common (I believe) AGPS is SUPL, which seems to be used by most phones. This involves sending your approximate location to an Internet server, which returns satellite data based on that approximate location.
To nobody’s surprise, in Android this is a Google server. I’m pretty sure most Android distros don’t give you any control over when it’s used, or which servers it uses. Anecdotally, my phone without Google Play services has a horrible time obtaining a GPS fix, so I suspect without GPlay it’s only using raw GPS, but I’ve not bothered to actually dig into it.
As I understand it, SUPL means even if you’re in aeroplane mode, if you have an Internet connection over WiFi you might still be leaking (approximate) location data when using GPS.
I learned about this from this excellent series of blog posts, which is a very thorough comparison of various Android ROMs’ privacy. It has a background section (search for “Assisted GPS”) in each of the ROM-specific posts which explains it better than I can.
 7·2 months ago
7·2 months agoInteresting, thanks for doing the research!
As an extreme non-expert, I would say “deliberate removal of a part of a model in order to study the structure of that model” is a somewhat different concept to “intrinsic and inexorable averaging of language by LLM tools as they currently exist”, but they may well involve similar mechanisms, and that may be what the OP is referencing, I don’t know enough of the technical side to say.
That paper looks pretty interesting in itself; other issues aside, LLMs are really fascinating in the way they build (statistical) representations of language.
This is a good name for one of the main reasons I’ve never really felt a desire to have an LLM rephrase/correct/review something I’ve already written. It’s the reason I’ve never used Grammarly, and turned off those infuriating “phrasing” suggestions in Microsoft Word that serve only to turn a perfectly legible sentence into the verbal equivalent of Corporate Memphis.
I’m not a writer, but lately I often deliberately edit myself less than usual, to stay as far as possible from the semantic “valley floor” along which LLM text tends to flow. It probably makes me sound a bit unhinged at times, but hey at least it’s slightly interesting to read.
I do wish the article made it clear if this is an existing term (or even phenomenon) among academics, something the author is coining as of this article, or somewhere in between.
GPT-4o mini, “Rephrase the below text in a neutral tone”:
This name is appropriate for one key reason: I have not felt the need to use an LLM for rephrasing, correcting, or reviewing my writing. This is also why I have not utilized Grammarly and have disabled the “phrasing” suggestions in Microsoft Word, which often transform a clear sentence into something overly corporate or generic.
Although I wouldn’t categorize myself as a writer, I have been intentionally editing myself less than usual lately to avoid the typical style associated with LLM-generated text. This approach might come across as unconventional at times, but it can also make for more engaging reading.
I also wish the article clarified whether this term is already established in academic circles, if the author is introducing it for the first time, or if it falls somewhere in between.
“avoid the typical style associated with LLM-generated text” – slop!
 2·2 months ago
2·2 months agoYeah, even though I have a bit of background I can’t really make heads or tails of that OpenSearch doc at a glance, it’s dense stuff.
In my experience knowing the keywords to stick in a search engine is often half the battle; there are plenty of resources out there on “vector databases”. “Semantic search” from the lede of the OpenSearch doc might be another good one to have around.
Feel free to ask me any other questions and I can try to answer to the best of my abilities, though again, not an expert and honestly I’ve never actually used these myself beyond toy examples.
I’m not an expert, but it sounds like you want an embedding+vector database. This essentially extracts the part of an LLM that “understands” (loaded term, note the quotes) the text you put in, and then does a lookup directly on that “understanding”, so it’s very good at finding alternate phrasings or slightly differing questions.
There’s no actual text generation involved, and no need to retrain anything when adding new questions.
OpenSearch has an implementation (which I learned about just now while writing this comment and thus cannot vouch for); you could start there.
Thanks! Looks like that 180’s showing on my noob free tier now too. Pretty much the same thing Elpis did; through the strait itself no problems but then a sudden 180 in the Gulf right about the same place as Starry. Elpis came to a standstill almost immediately after but Starry is allegedly still doing 8.1 kn, strange.